
Hyperspace นั้นเป็นเครื่องมือที่จะทำให้การค้นหาข้อมูลที่อยู่บน Azure Data Lake สามารถทำได้ง่าย และมีประสิทธิภาพสูงมากๆ
แถมรองรับหลายภาษาด้วย เช่น
- Python
- Scala
- .NET
เราสามารถใช้ Hyperspace กับ Dataset ที่เรามี ไม่ว่าจะเป็นข้อมูลแบบ CSV, JSON, Parquet ซึ่งพอนำมาใช้งาน เราจะสามารถทำสิ่งที่เรียกว่า indexing กับข้อมูลพวกนี้ได้เหมือนกับระบบฐานข้อมูลที่เรารู้จักกันดี
ซึ่งการทำแบบนี้เหมือนเรามีการสร้าง index layer ขึ้นมาอีกชั้นหนึ่ง เหมือนภาพด้านล่าง
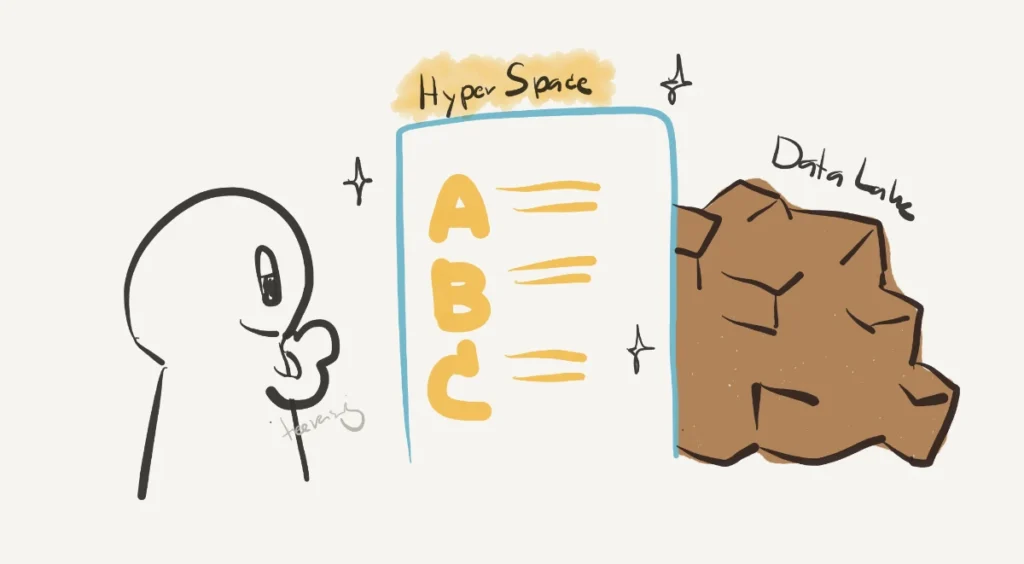
และถ้าข้อมูลใน Data Lake มีการเปลี่ยนแปลง เราก็แค่ refresh ตัว index อีกรอบเพื่อให้มันอ่านข้อมูลใหม่นั่นเองครับ
วิธีการใช้งาน
การเรียกใช้ Hyperspace ก็จะตรงไปตรงมาเหมือน library อื่นๆ เลย เช่นถ้าเราใช้ภาษา Python
from hyperspace import *
from com.microsoft.hyperspace import *
from com.microsoft.hyperspace.index import *
# สร้าง instance ของ Hyperspace
hyperspace = Hyperspace(spark)
# สร้าง indexes: กำหนดชื่อ, ชื่อของคอลัมภ์ที่จะทำ index และชื่อของ included columns
indexConfigUsers = IndexConfig("indexUser", ["userId"], ["FullName"])
hyperspace.createIndex(aDataframe, indexConfigUsers) # only create index once
hyperspace.indexes().show()ถ้าสนใจ ไปลองเอามาใช้งานได้ ฟรี เป็น opensource ของ Microsoft โดยตรงครับ